You can now search the Bluge Labs website, and it’s powered by Bluge search technology! Why am I so excited about this one new box in the menu?
First, I think it’s a really important milestone for the Bluge project to be able to self-host it’s own code for searching the documentation. Second, the implementation is significantly cleaner and easier to maintain than our previous attempts to make the blevesearch.com website searchable. Finally, this solution uses the new Directory abstraction in Bluge, highlighting something that just isn’t possible with Bleve today.
Read on to learn more about how this implemented.
Background
The Bluge Labs website is static, with the source code hosted on GitHub. We use the Hugo site generator to build the website. The site is built and hosted using Netlify.
In the past, using a Go search technology like Bleve or Bluge to search a static website, meant hosting a Go executable somewhere. But, the whole point of static site is that you don’t want to deal with these hosting issues.
Serverless Functions
In 2018, Netlify introduced Functions as a way to add dynamic capabilities to your website. It’s basically a streamlined deployment wrapper around AWS Lambda in Go.
So, this is the key ingredient to this new static site search solution, we just need to build a Go executable, conforming to right serverless APIs, that can answer search queries.
Rough Sketch of the Solution
- Generate the Website
- Build Search Index
- Compile search executable
- Bundle for Netlify Deploy
Generate the Website
Building a website with Hugo is usually pretty simple, we just run hugo. The only change we’re going to make here is to add a JSON output for our site’s pages.
[outputs]
page = ["HTML", "JSON"]
To go along with this change, we add a new layout for the JSON:
{{ dict "title" .Title "date" .Date "type" .Type "permalink" .Permalink "content" .Plain | jsonify }}
This just chooses the meta-data we want, along with a plain-text version of the page content and builds valid JSON. We’ll consume this JSON in the next phase when building the index.
Build Search Index
In the future we may try to extract this into a more reusable component, but for now we’ve just thrown together a simple indexing application using the Bluge APIs.
It’s just over a hundred lines, with the following logic:
- Create a Bluge OfflineWriter
- Recursively walk the website (filepath.Walk) looking for
.jsonfiles. - Parse the JSON
- Build a Bluge Document
- Add it to the Index
We use the OfflineWriter here because it will merge the final index down to a single segment, which is more optimal for read-only use later.
Let’s take a closer look at how we build the Bluge Documents:
doc := bluge.NewDocument(page.PermaLink).
AddField(
bluge.NewTextField("title", page.Title).
StoreValue()).
AddField(
bluge.NewKeywordField("type", page.Type).
StoreValue().
Aggregatable()).
AddField(
bluge.NewTextField("content", html.UnescapeString(page.Content)).
StoreValue().
HighlightMatches()).
AddField(bluge.NewCompositeFieldExcluding("_all", []string{"_id"}))
pageDate, err := time.Parse(time.RFC3339, page.Date)
if err == nil && !pageDate.IsZero() {
doc.AddField(bluge.NewDateTimeField("updated", pageDate))
}
We’re using the document’s PermaLink as a unique identifier. We’re indexing the page’s Title, Type, and Content. If the page has a valid date, we index that as well. Finally, we have a composite field named _all to let us search without specifying a field.
The full source for this utility is part of the website source tree bluge_index_dir.
Compile Search Executable
This is the serverless function which will need to do two things:
- Open the index
- Start a handler that will
- Parse incoming search queries (JSON)
- Search the index
- Format response (JSON)
That first step, opening the index is the surprisingly interesting part of the solution. How will this serverless executable access the index? The Netlify Functions documentation describes deployment of Go and JavaScript functions via zip file. So my original plan was to include the index inside that zip file. Unfortunately, I was only ever able to get zip file deployment to work with JavaScript, with Go it seemed it only wanted to deploy the raw executable.
I needed a solution to ship the index as a part of the executable. Go has many utilities/libraries for packing binary data into an executable, but none of them quite worked the way I wanted. My solution was to add each file in the index as an additional segment in the ELF executable. But, how would Bluge know how find or read this data? Out of the box, Bluge only supports working with directories and files on the file-system.
Fortunately, Bluge introduce a new abstraction, the Directory. The Directory interface allows a complete separation of concerns between the Bluge search logic, and how to find/load/save index segments and snapshots from whatever medium they exist.
Utilizing this new abstraction, I have introduced a new Directory implementation named bluge_directory_elf. This module provides a read-only directory implementation capable of accessing index segments and snapshots stored within the application executable itself. It also includes a utility application for embedding indexes into an executable (using the host operating system’s objcopy command).
This shows the power of this new Directory abstraction, we’re able to use Bluge in an environment we did not anticipate when we introduced the abstraction. Bleve lacks this abstraction, and would not be able to operate in this environment.
Pulling, all this together, our serverless function starts by opening the index using the bluge_directory_elf implementation. This knows how to list the segments, find the Bluge index, and mmap regions of the executable containing search data as needed.
The rest of the application is just marshaling/unmarshaling JSON, and invoking the desired Bluge search APIs.
The full source for the serverless function can be found in the website source tree site-search.
Bundle for Netlify Deploy
Now that our site build is more than just invoking hugo we have introduced a Makefile
To review, the steps are:
- Build Website (
hugo) - Compile our indexing application
- Run indexing application to build search index
- Compile our serverless search function
- Run a command to add the search index files to the serverless executable
- Copy the final serverless executable to the
functionsdirectory
The Front-end
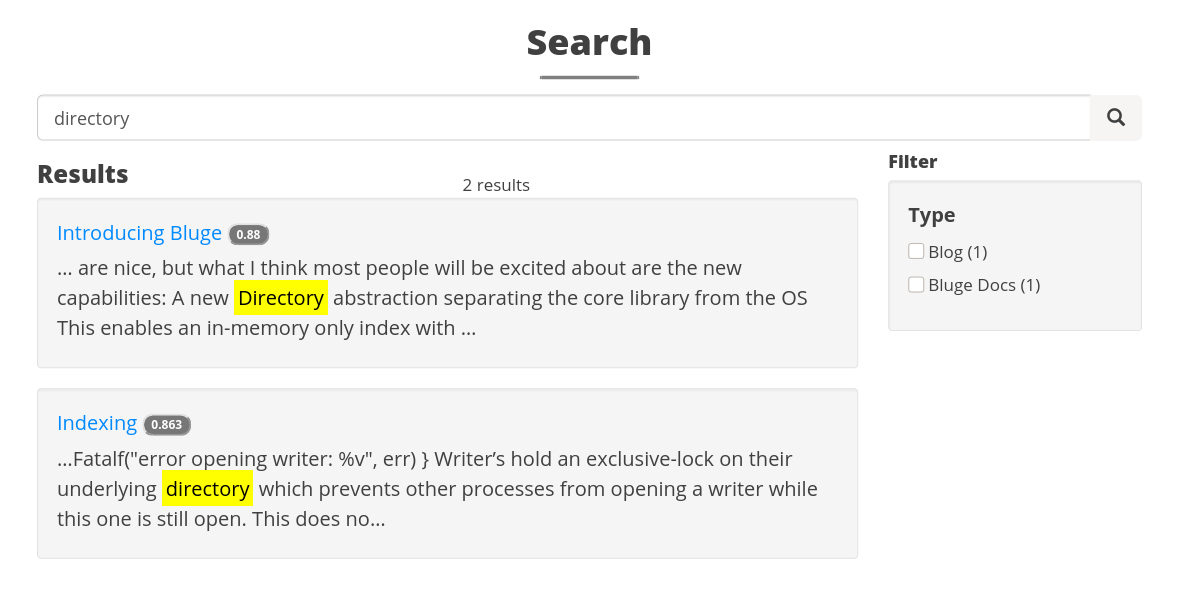
Out front, our search page makes XHR requests to the serverless function, and we use handlebars templates to render the results.
Conclusion
The Netlify Functions capability offers a great solution to allow searching a static website. While embedding the index inside the ELF executable was unexpected, it ended up offering a great way to demonstrate the power of Bluge’s new Directory abstraction.
Bluge is still in a Developer Preview, but as it matures, we hope to make this a more packaged solution for other static websites using Hugo/Netlify.